Whole Genome Sequencing for Revealing the Point Mutations of SARS-CoV-2 Genome in Bangladeshi Isolates and their Structural Effects on Viral Proteins
Abstract
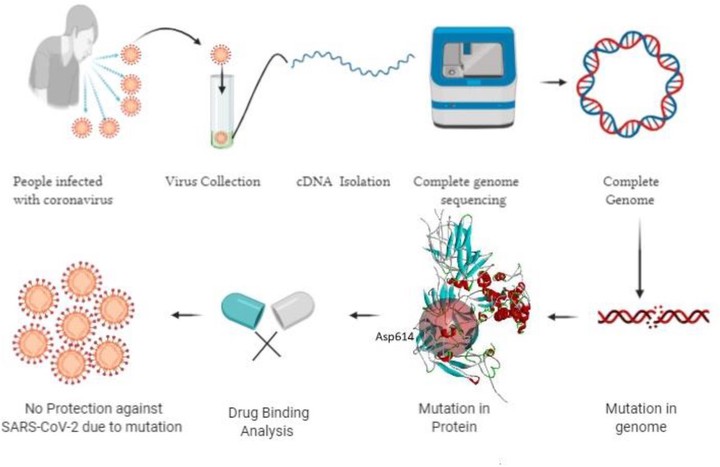
Coronavirus disease-19 (COVID-19) is the recent global pandemic caused by the virus Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2). The virus has already killed more than one million people worldwide and billions are at risk of getting infected. As of now, there is neither any drug nor any vaccine in sight with conclusive scientific evidence that it can cure or provide protection against the illness. Since novel coronavirus is a new virus, mining its genome sequence is of crucial importance for drug/vaccine(s) development. Whole genome sequencing is a helpful tool in identifying genetic changes that occur in a virus when it spreads through the population. In this study, we performed complete genome sequencing of SARS-CoV-2 to unveil the genomic variation and indel, if present. We discovered thirteen (13) mutations in Orf1ab, S and N gene where seven (7) of them turned out to be novel mutations from our sequenced isolate. Besides, we found one (1) insertion and seven (7) deletions from the indel analysis among the 323 Bangladeshi isolates. However, the indel did not show any effect on proteins. Our energy minimization analysis showed both stabilizing and destabilizing impact on viral proteins depending on the mutation. Interestingly, all the variants were located in the binding site of the proteins. Furthermore, drug binding analysis revealed marked difference in interacting residues in mutants when compared to the wild type. Our analysis also suggested that eleven (11) mutations could exert damaging effects on their corresponding protein structures. The analysis of SARS-CoV-2 genetic variation and their impacts presented in this study might be helpful in gaining a better understanding of the pathogenesis of this deadly virus.